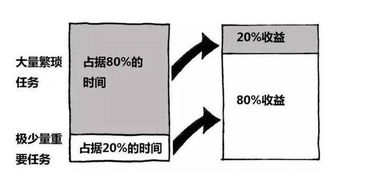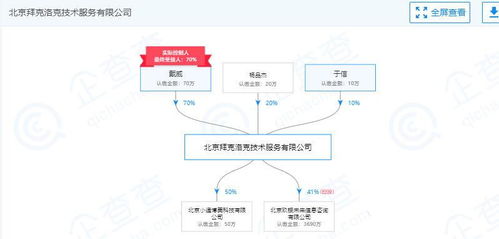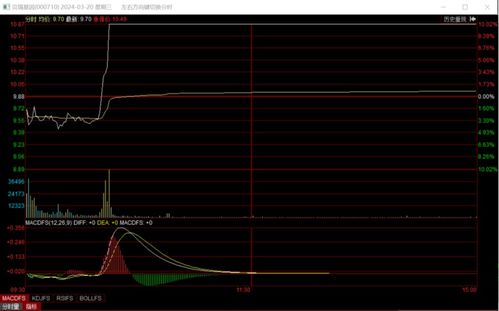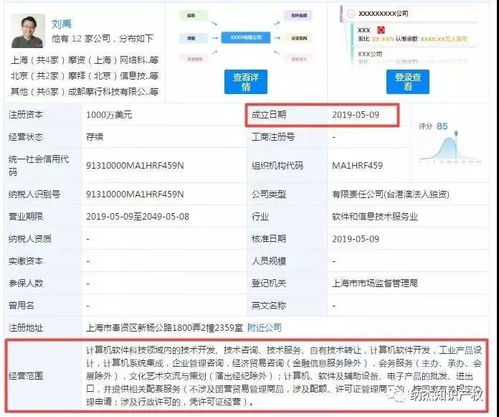
图片文字识别(OCR,Optical Character Recognition)软件已成为现代计算机应用中的重要工具,它能将图片中的文字信息转换为可编辑、可搜索的文本数据。在电脑上操作这类软件通常非常直观,同时其开发过程也体现了计算机软件技术的进步。
一、图片文字识别软件在电脑上的基本操作流程
- 安装与启动:用户首先需要从官方网站或可信来源下载并安装OCR软件,如Adobe Acrobat、ABBYY FineReader或免费工具如Tesseract。安装完成后,双击图标启动程序。
- 导入图片:软件界面通常提供“打开”或“导入”按钮,支持常见图片格式(如JPG、PNG、PDF)。用户可通过拖放文件或浏览文件夹方式添加图片。
- 识别设置:高级OCR软件允许用户调整识别参数,例如选择语言(如中文、英文)、设定输出格式(如Word、TXT),并启用版面分析以保留原始排版。
- 执行识别:点击“识别”或“转换”按钮后,软件会快速分析图片内容,将图像文字转为文本。过程中可能显示进度条,用户可实时查看结果。
- 校对与导出:识别完成后,软件通常提供文本编辑器供用户校对和修改错误。导出为所需格式,完成整个操作。
二、计算机软件开发中的OCR技术实现
在软件开发层面,OCR功能的集成涉及多学科技术:
- 图像预处理:开发人员需编写算法对图片进行降噪、二值化和倾斜校正,以提高识别准确率。例如,使用OpenCV库处理图像。
- 文字检测与分割:通过机器学习模型(如基于深度学习的YOLO或CNN)定位图片中的文字区域,并将其分割为单个字符。
- 字符识别:核心部分依赖训练好的模型,如LSTM(长短期记忆网络)或Transformer,将字符图像映射到文本。开源引擎Tesseract是常用工具,开发者可通过API集成到自定义软件中。
- 后处理与优化:软件需包括自然语言处理(NLP)模块,用于纠正拼写错误和优化语义连贯性,提升用户体验。
三、应用场景与开发趋势
OCR软件广泛应用于文档数字化、数据录入和教育领域。在计算机软件开发中,随着人工智能的发展,OCR技术正朝着更高精度、多语言支持和实时处理方向演进。开发者可通过云服务(如Google Cloud Vision API)快速部署,或利用边缘计算实现离线功能,满足多样化需求。
图片文字识别软件的操作简便性背后,是计算机软件开发中复杂的算法与工程实践。用户只需几步点击即可完成转换,而开发者则持续优化模型,推动这一技术的普及与创新。